My todoListo Adventure
Part 1: The Making of todoListo
16/02/2024A nostalgic retrospect of how todoListo started, how it took shape and how it turned from a demo into a product. …
Part 1: The Making of todoListo
16/02/2024This blog series describes my experience with todoListo. I highly recommend that you have a look at it before reading the text, so that you know what this is about.
Why I started todoListo
It took me a while to find out what I wanted to do in my professional life. I spent quite some time in science and then switched to freelancing. But what exactly was I offering? Was I now a software developer? A consultant? A coach? I saw myself in all of these roles, but I found that there is one thing I enjoyed most: hacking away on new software projects to bring ideas to life.
I had done this kind of software prototyping at Intuity for Sort-it and in other projects. And when I think back, this is also what I did in my university research. Computer science is all about prototyping. You don't implement productive systems, what would be the point? You only implement to a point where you can test your assumptions about a certain procedure. And this creative-technical process of turning an idea into (more or less) working software is what I would like to earn my living with.
Prototyping can mean a lot of different things and with my notion of prototyping also comes with a notion of agile software development (see my blog series on agile software development). So it is hard to explain to potential customers what I mean with software prototyping
and to gain the necessary trust. Therefore I thought it would be fun for me and demonstrative for others if I showcased a prototype on my website.
The impulse to start this particular project came from a presentation on Decision Making that I was giving around the time between my blog series about goals and decision making. Decision making is my central scientific interest and I love to tell others about how we can make good decisions in real life, as opposed to advice from theoretical models that are presented everywhere. But after that presentation, and having written some of this in blogs, I became aware that talking does not fully convey the message. It would be much better to demonstrate those concepts. And one specific decision we all have to face several times per day is what to do next. So there was the idea of a to-do list application.
The Prototype
October 2021: The Journey Begins
Starting the project was easy. I had been managing my to-do's in a note-taking program for years, so the requirements seemed pretty clear (I explain my procedure in a series of YouTube videos). And I was looking forward to get a functionality that I had always missed in the note-taking program: tags to flag tasks as belonging to a certain project. In this way I could switch between a view of tasks by tags and one by time (my default).
So I started to put this schema into a web application on my website. Since I had done React applications in ClojureScript before, the setup was quick. This is a screenshot of my first commit, after a day or so of work.
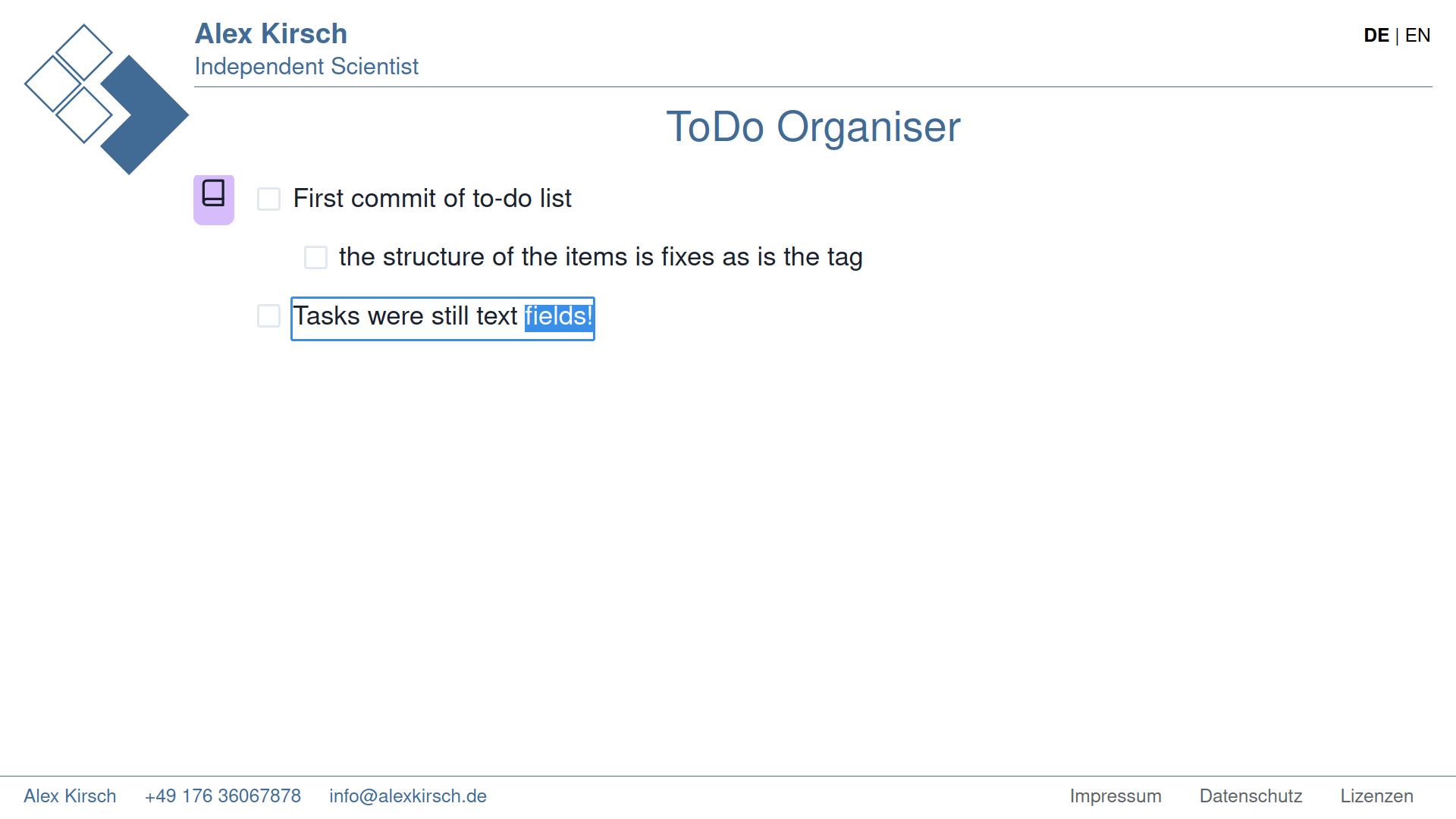
End of year 2021: Ready to test
I started testing with my real to-do list the moment that I could type in tasks (I could not even reorder them at first!). I was very surprised how quickly I was moving from my note-taking program to my new app. My to-do list is a vital tool for me. Losing my to-do list would be as tragic as my laptop being stolen. So I thought I would move very carefully, using the new app only for a single day, and at the end of the day, moving the information to my traditional list. But I put all good intentions aside and moved all my to-do's to my new app within a few days. It was scary, but also showed that I was on a good way if I was willing to move my treasure to this app so quickly.
After two months of work, I deployed the app on a password-protected page on my website to use it every day. This is what it looked like:
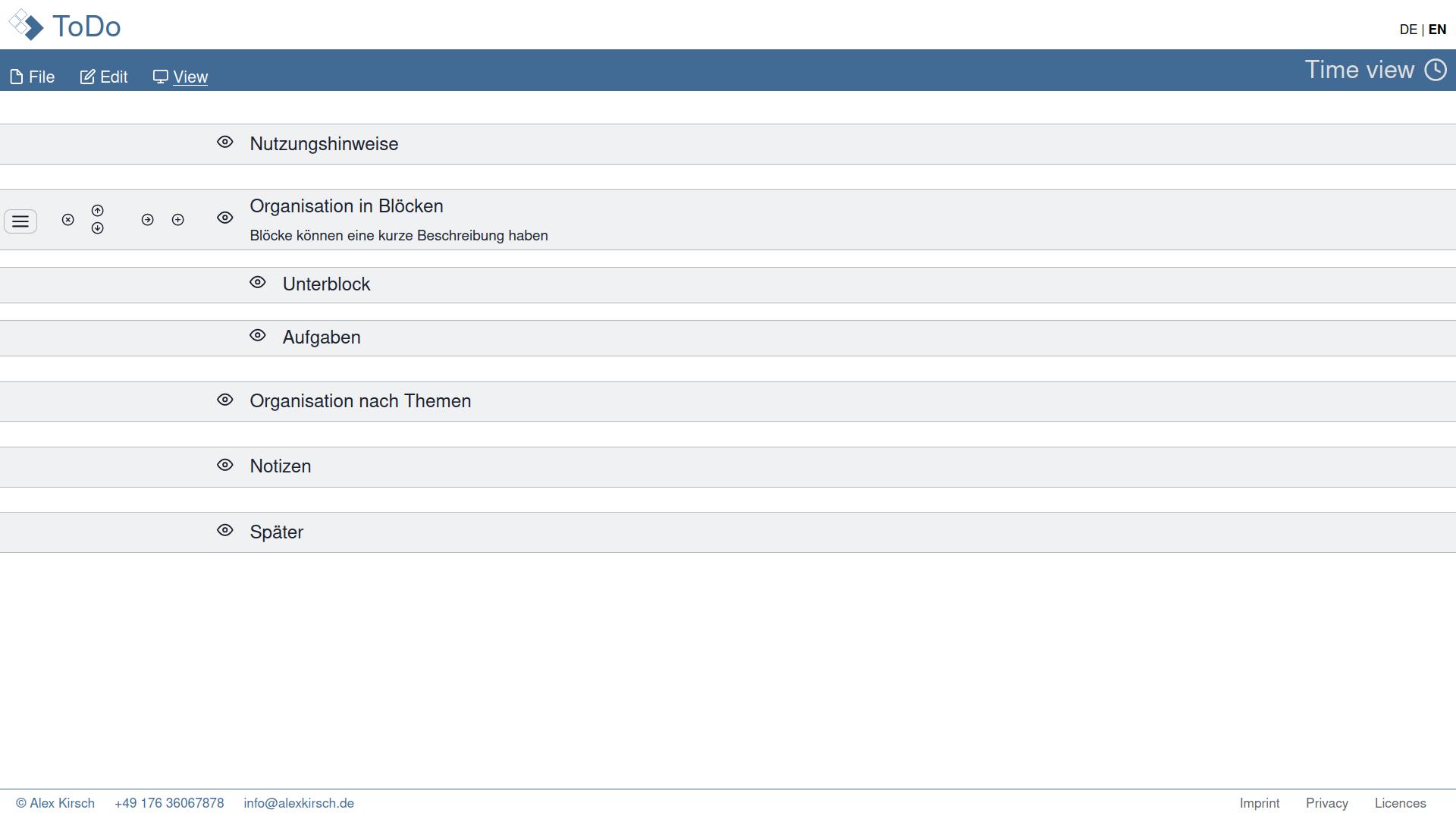
February 2022: More users and features
While I was using my new to-do app, I became aware of a shortcoming in my procedure that had always been around, but that I had never bothered to solve. I liked to add additional information to my tasks, such as relevant web links or a note on where I had stopped working. I would add such information directly on a task or in between tasks. But if that got too long, the to-do list got cluttered and I would lose the overview that it was supposed to give me. So when I wanted to write down more about a task or a project, but I would do that on a different page (the note-taking program was organized in the typical hierarchy of pages). But to be honest: I usually forgot about the notes and found them a few years later. And even then, I often did not delete them, so it got harder and harder to keep an overview of such notes, so I mostly ignored them.
In my new app, I had already made sure that a lot of information fits into the task text (it is rather wide and can span several lines). And I thought that more extensive notes could still go into a note-taking program. They would get forgotten as always, but I didn't lose anything compared to how I had been working. But then I got the idea: why not add space for more extensive notes directly on the task? In retrospect, this idea looks trivial, but back then, it was a surprising insight. So I added a sidebar for adding notes. Since rich text editing is not easy, I built a cheap solution with a text area in which one could type in Markdown commands and a button to switch between the text area view and a rendered text view of that content. So I quickly got powerful formatting capabilities, needing only a library that converts Markdown to HTML (or in my case Hiccup format, working with ClojureScript). This solution was a typical prototyping-hack. It was enough to test whether this concept of notes would be valuable, but nothing you would give to a user in a productive system.
This is what the app looked like with notes:
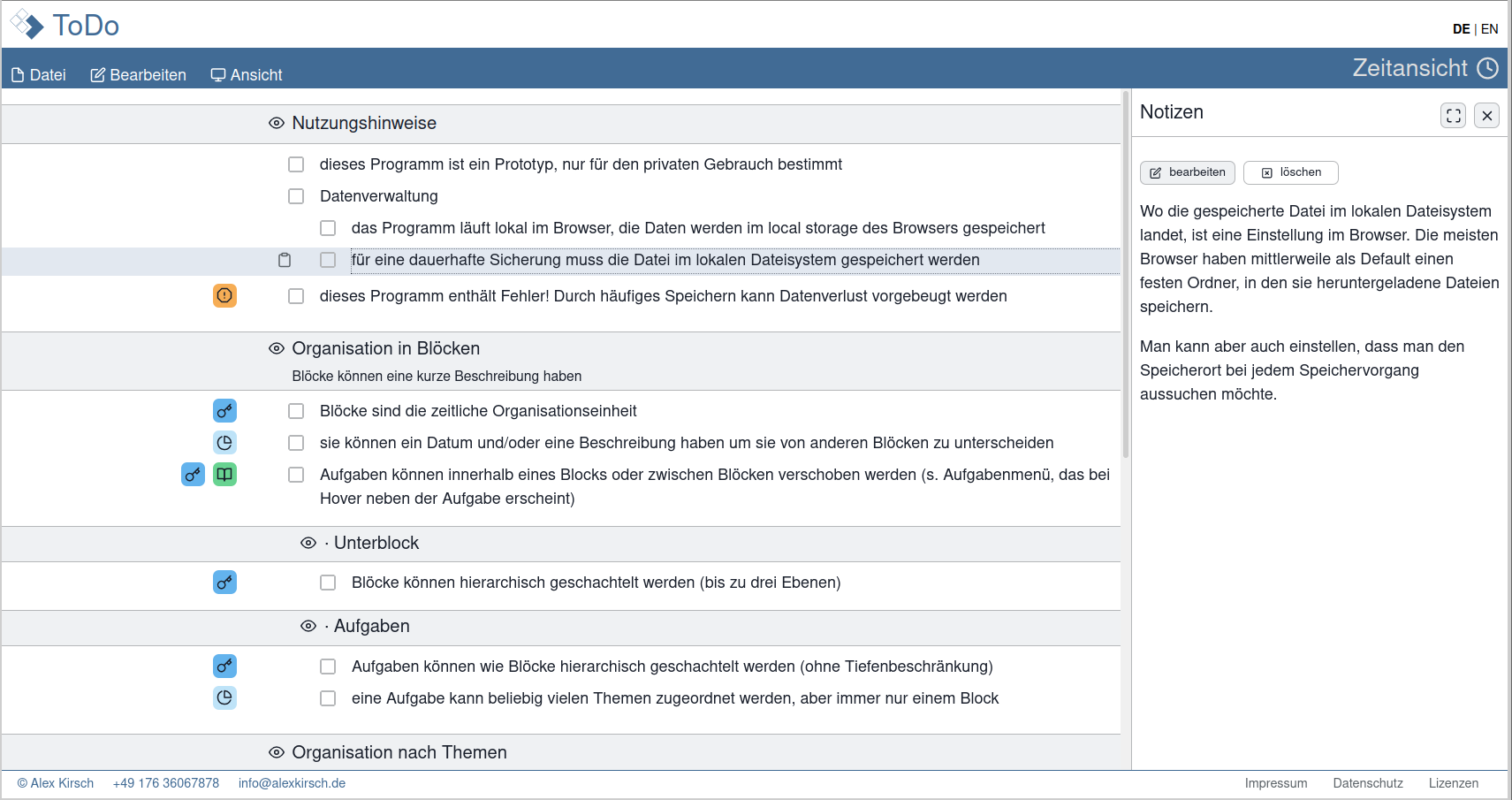
Around this time I also started to pass the link and password of the test website to a few friends. Some of their feedback was to be expected (such as the notes not being very user-friendly), but there were also some surprises. For example, one user completely forgot that there was a second view of tasks, the one ordered along tags, and she wondered how she could add new tags. And indeed, it was anything but obvious that there were these two views and how to switch between them.
I also found that tastes differ. In the prototype, I had tried to attach functionality directly to the objects on the screen. So blocks (representing time intervals or tags) had a set of small icons to move them around in their hierarchy. I thought that was a very elegant way of attaching them: visible, but not too obtrusive. It turned out that nobody liked them but me.
April 2022: From demo to product
By April, six months after I had started, my prototype was at the end of its lifetime. As we have just seen, some early design decisions turned out to be wrong, and the code was beginning to get unwieldy, so I could not make these changes without a major effort. But I also had got used to this to-do list app. Even though it had shortcomings, it was more fun to work with it than with my old note-taking solution. And I had lots of ideas of how to improve it. In particular, I was craving for a backend to store the data on a server so that I could access it from different devices. I am using different computers during the week and on the weekend, so whenever I remembered something that needed to be done for work during the weekend, I had to sent myself e-mail!
So to continue was not exactly a well-thought-out decision. The project was fun, I wanted this app and I had so many ideas that it would have been hard to stop me at this point. And maybe that was good. If I had taken the time to seriously think about the implications (see the next parts below), I would probably have stopped at this point, wondering for the rest of my life what this project might have led to. At least I realized that this was a major switch in the project scope. I was aware that the additional effort would only make sense if I considered this project as a software product rather than just a demo.
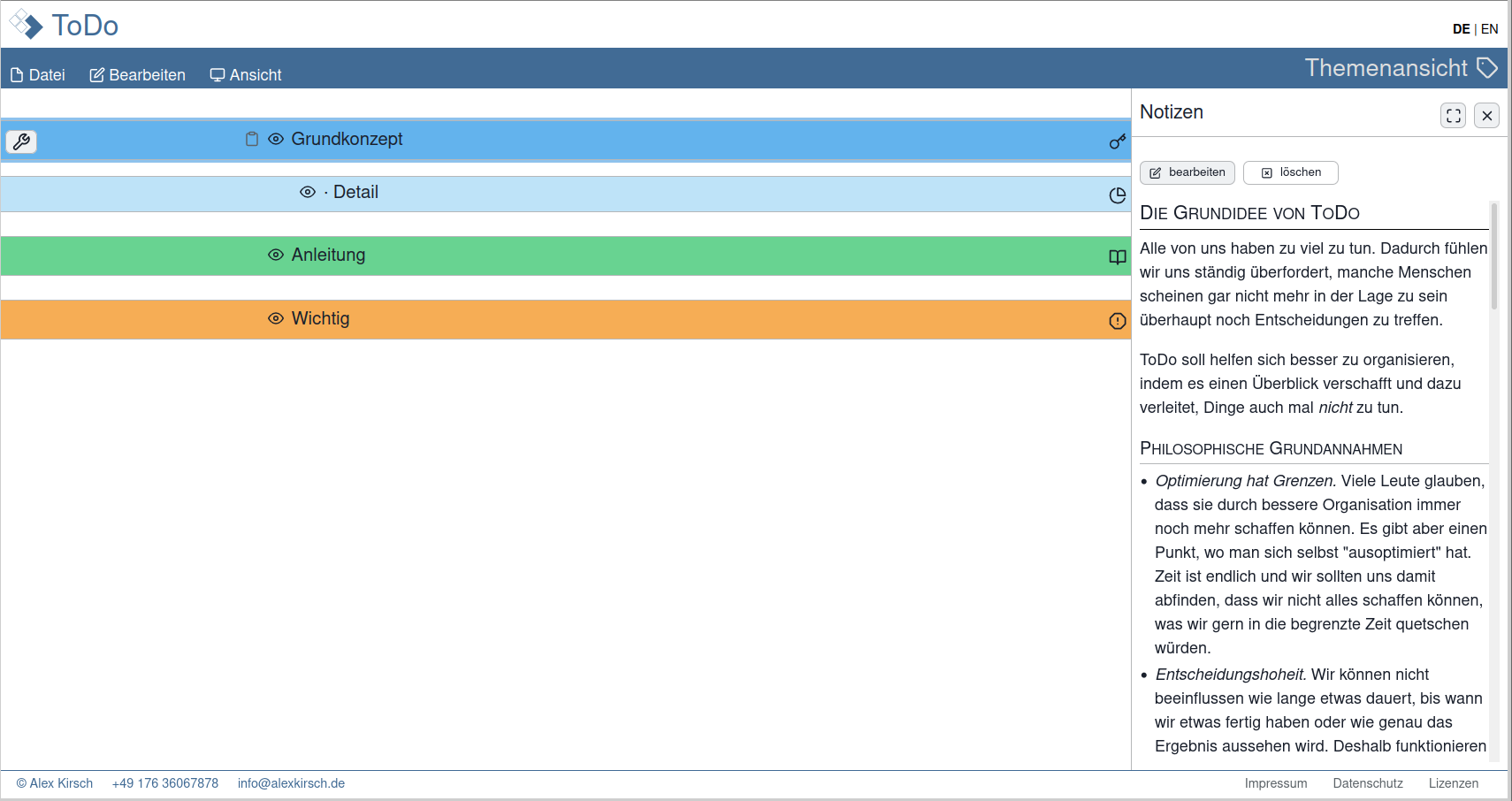
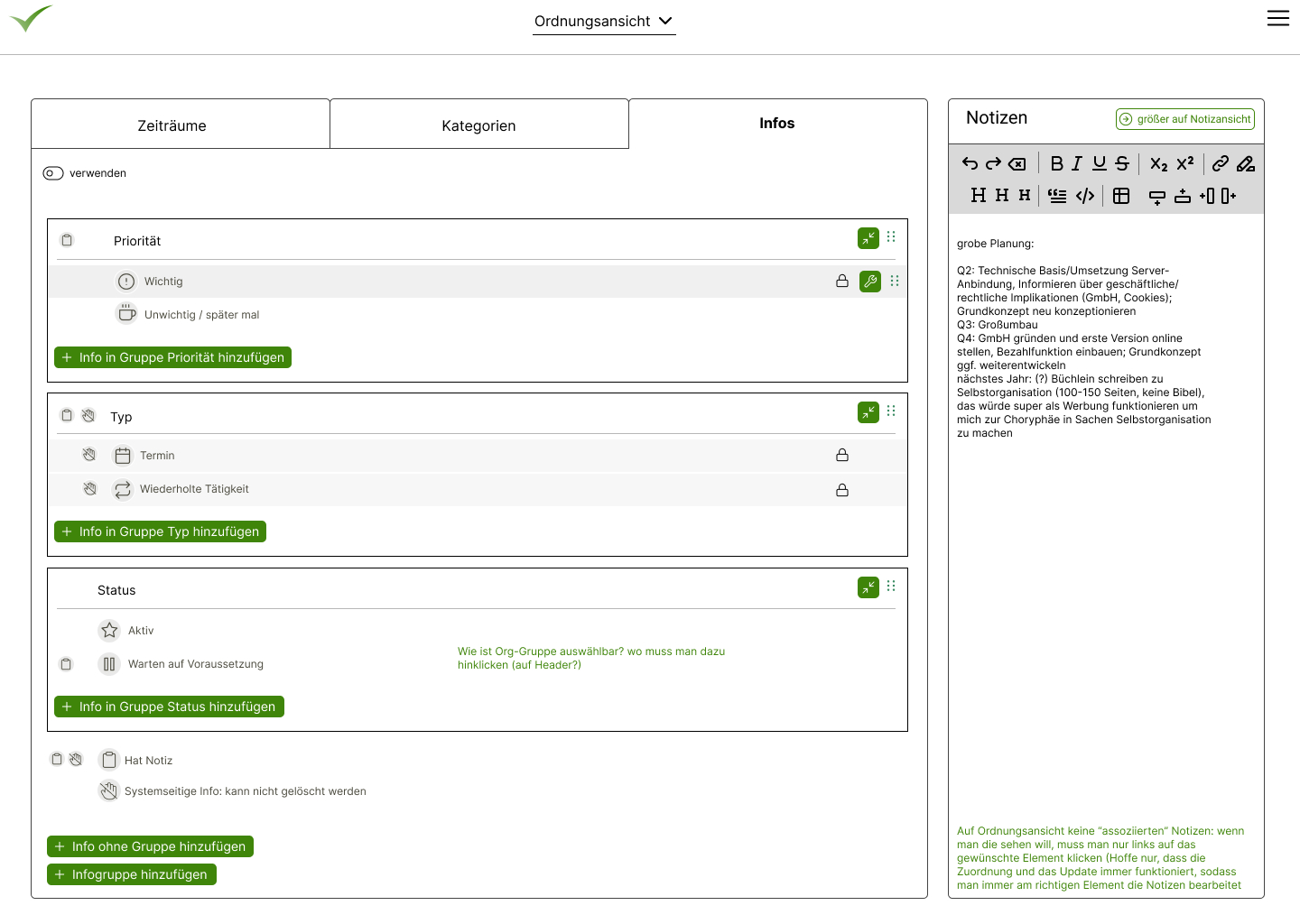
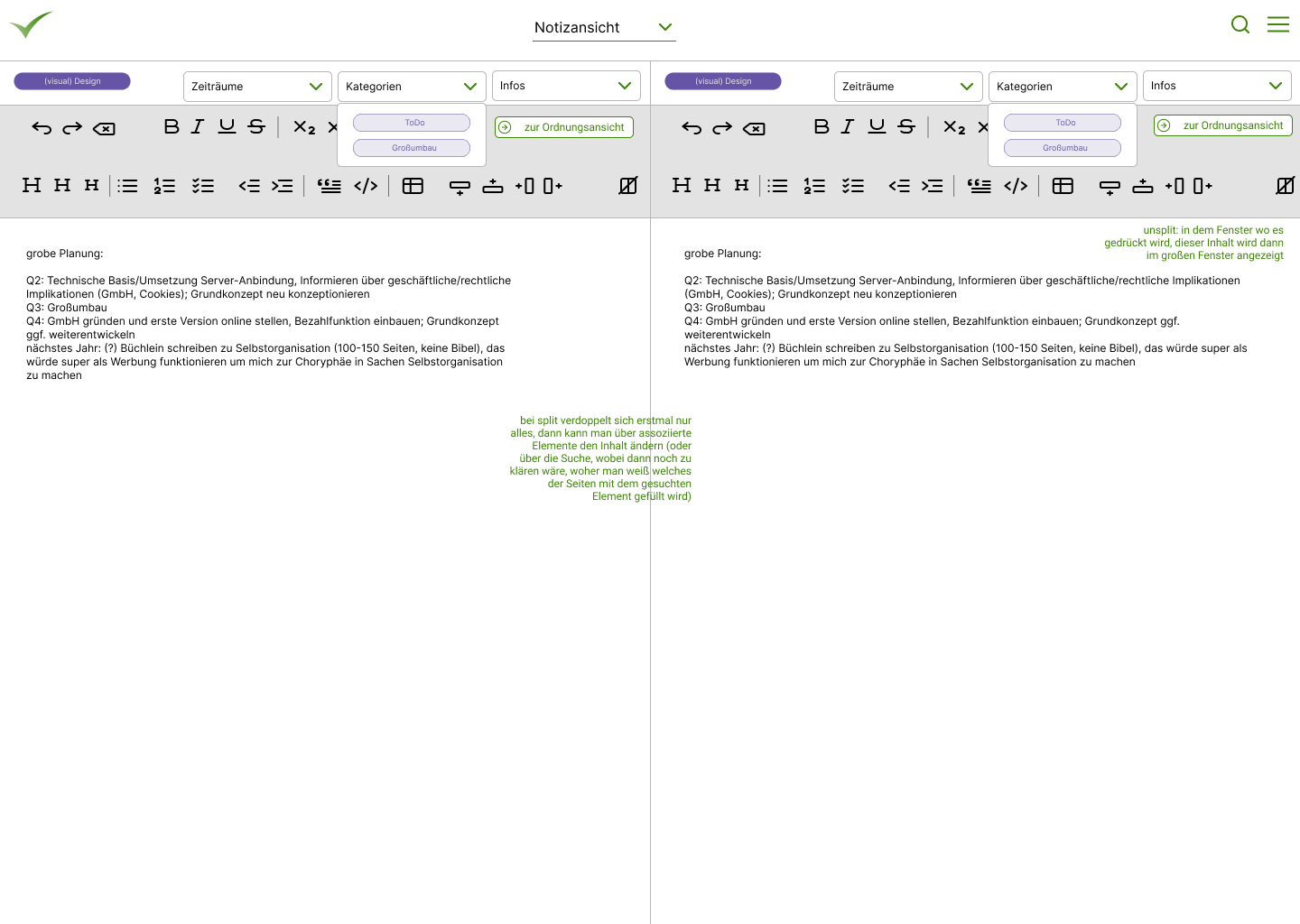
So first I took the time to revise the whole visual concept. The tagging that I had so much desired from the start of the project turned out to be less useful than I thought. Not because tagging didn't work, but because I was overusing it so much that everything was just a blob of colors. Therefore I split the concept into categories (e.g. to represent projects) and infos (for more generic conceps such as has high priority
). The notes got their own screen in addition to their place in the sidebar (to enable editing of notes side-by-side and as a solution for mobile devices). More changes and learnings from the prototype are described in Part 2 below. Here are some of my design sketches:
todoListo also started to get an identity. The main color changed from blue to green and the search for a logo started. It was clear to me that it should be some kind of check mark. I cannot remember exactly when the name was final. The working title so far had just been ToDo
and I liked to pronounce it toe-doe
, so rather like the Spanish word for all
. So I was happy to finally find a name that would both make the app recognizable as a to-do list and let me keep my baby's nickname. You can learn more about the name in this YouTube video.
The Real Thing
I took about three months to reconsider todoListo's visual and technical design. In July 2022 I started to implement from scratch. Since I had a pretty clear concept of what it should look like and with the experience of the prototype, I imagined that I would reimplement the frontend over the summer, then quickly add the backend (basically just a database or not even that, it should just store the user's data), get a payment provider for the version with server storage, and I might be done until the end of the year, or maybe until the spring.
Well,… It took slightly longer. In my defense, I have to add that I was hit rather heavily by COVID in August 2022 and it took me several months to recover fully. But still it is hard to make excuses for the final release date: October 27, 2023, to the day two years after my first commit of the prototype, and almost a year later than I had originally wished for.
The following parts explain in more detail why the implementation took so long. Part 3 showcases the difference between a prototype and productive software, so basically why I underestimated the reimplementation of the pure frontend. Part 4 goes into my miscalculation of the effort the the backend
. Part 5 summarizes my learnings from the project and how I imagine it to continue.
Part 2: The Power of Prototyping
23/02/2024Starting a software project with naturalistic prototyping is the fastest, most reliable and inexpensive way to understand the technical and functional requirements. I discuss some examples from todoListo to illustrate how prototyping improved the original concept and the value of prototyping for software development in general. …
Part 2: The Power of Prototyping
23/02/2024Bootstrapping Software Development
How do you start a software project? The traditional wisdom tells you to start by analysing and documenting the requirements, then start to design the software architecture and user interface, and then implement and test the software. In any realistic setup, you will have to repeat this process, e.g. when you add more features. The main difference between traditional approaches (aka waterfall model
) and more recent trends (aka agile development
) are the time scales. While old school assumes long iterations, where one phase is supposed to be finished before starting the next, recent wisdom acknowledges that more frequent iterations are necessary and that the steps are executed in parallel.
In the design phase, both for the architecture and the user interface, prototyping is an established method and it can mean different things. You might try a new technology or library and call that a prototype. Or you can have visual prototypes like mockups that show how different screens might look like. The purpose of such prototypes is to clarify a certain detail so that the resulting specification for the software becomes more reliable.
But all these efforts lead to specification documents (possibly including images and click dummies of the user interface), at best. When people see such documents and talk about them they are in theory mode
, they don't experience the system in a situation. Gary Klein has coined the term naturalistic environment
[1]. Contrary to common belief and propaganda, people are very good decision makers given the complexity of the world we live in [2]. So when we build a prototype, we can have people use it in the situational context that they will be using the final software and this is where the real requirements come to light. There are so many things we do that we are not aware of, and this is why we find it hard to list them as requirements. But the moment we use software and it is not fully intuitive or a feature is missing, we will realize it right away.
This article is no attempt to categorize prototypes, but I want to mention one more variant of prototypes: the Minimum Viable Product (MVP). Its purpose is similar to the naturalistic prototype I describe here, meaning a full system that can be tested in realistic setups. For MVPs everyone seems to have a very specific definition of what it is, but no two people have the same definition. One controversial issue is whether an MVP is one specific instance of the software (as the word minimum
implies) or whether iterations are allowed. It also contains the word product
, indicating that it is in a rather advanced state of development, so the playful character of a naturalistic prototype and the readiness to start over are missing. This is why I try to avoid the term MVP.
Naturalistic Prototyping
Instead of starting with a lengthy analysis, I suggest to start software projects by programming as soon as we have a rough idea of what the project is about. In the case of todoListo I could start right away, because I knew (or thought I knew) how I wanted to work with a to-do list. For software that you don't intend to use yourself, some more input may be necessary, but definitely not to the point of a full requirements specification or a full design of all the screens of a user interface. The moment you sit down and code, the important issues will reveal themselves, both on a technical level and an interaction level.
With running software in front of you (that may have bugs and lots of limitations) the communication with stakeholders becomes much more specific. Instead of just looking at images or text, everyone can take the mouse, click around and experience what the interaction feels like. It can be used to at least simulate realistic working situations or might even be used carefully in the real environment. The communication also gets much more realistic about what is technically possible. The person who has coded the prototype has acquired a feeling of what is easy and what is hard to do, so settling on the scope of the project turns from a wishlist into an informed business decision.
It is not always easy to decide how much functionality a naturalistic prototype should include. The most important is the specific functionality of the software. In todoListo this was a list of items with a checkbox and ways to add information to them and work with them. More generic or laborious functionality should be left out or simulated in some way. For example, error messages can be greatly simplified. Instead of providing a decent message and a way out as you would in productive software, just write a message into a developer console or don't even test for error cases. A prototype may crash, no problem.
Another example for simplification in prototypes is the data storage, e.g. by saving data into a file instead of implementing a database connection or a connection to a server (see Part~4 on the complexity of distributed systems). This restricts the options of using the prototype in realistic settings, but it can be used on a temporary basis or one might build a little script that takes data from a file and stores it into an existing database. This will leave the systems decoupled and still allow for testing in the naturalistic setting. What is important, though, is that you start to use real or at least realistic data from the start.
Case Studies
I have been using todoListo from the day I could enter tasks. Here are a few discoveries I made when using it myself or from the feedback I got from my test users.
Usability: How the Dashboard was born
The most basic question for any user interface and one we hardly ever think about: where to put the buttons? For example, how can a user move a task up or down in the list or indent it? One solution are keyboard shortcuts, but with phones and mice around, we also need some graphical option. My first attempt was to go modern and attach the functionality to each object, e.g. offering a menu when the user clicks on a task with the right mouse button. The problem with this solution is that it often violates the usability principle of visibility, it is often not clear that such a menu exists or the options are represented with icons that are hard to interpret. And when I observed myself and others using modern software with such interaction mechanisms, it turned out that the interaction is often not intiutive.
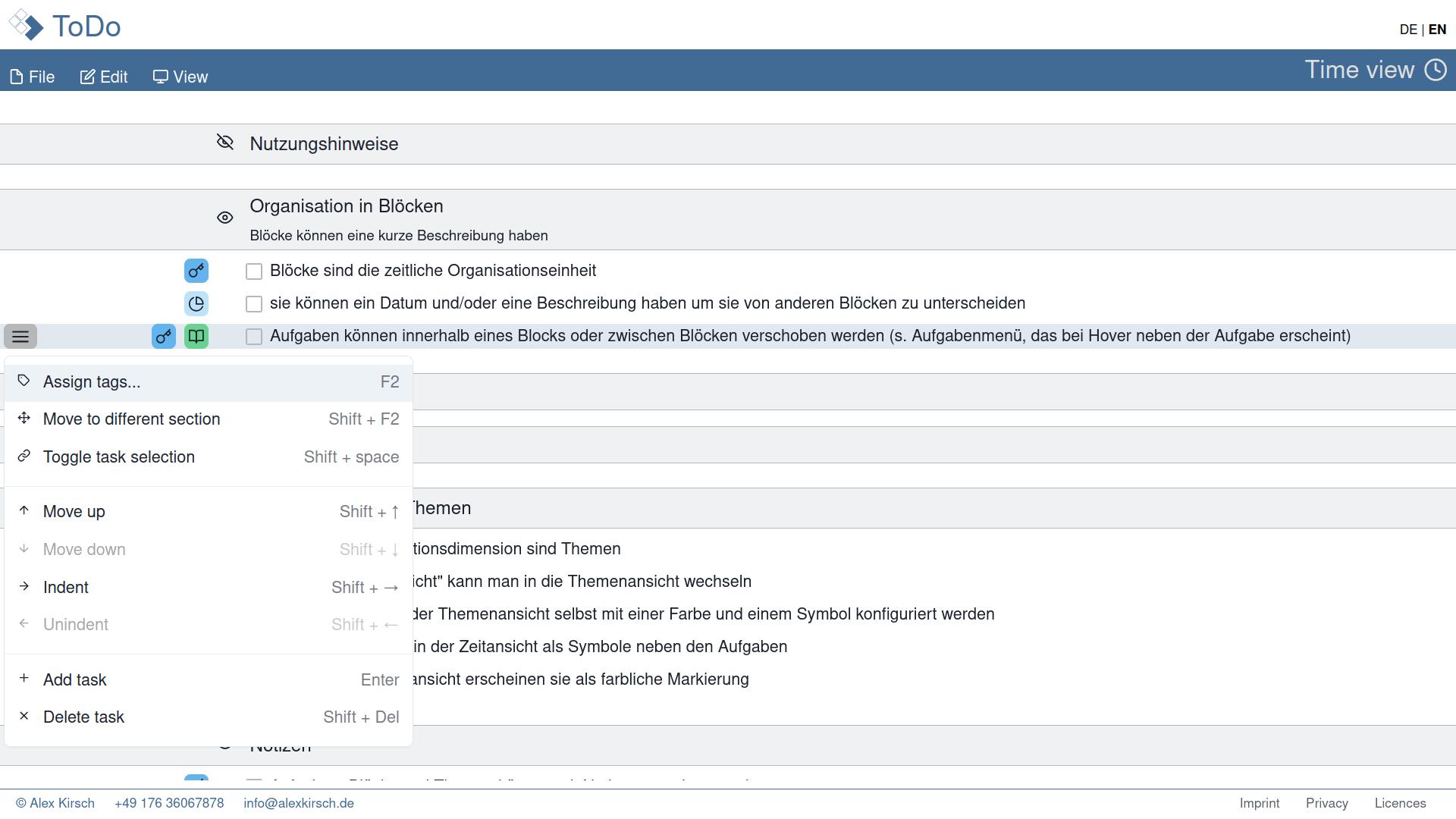
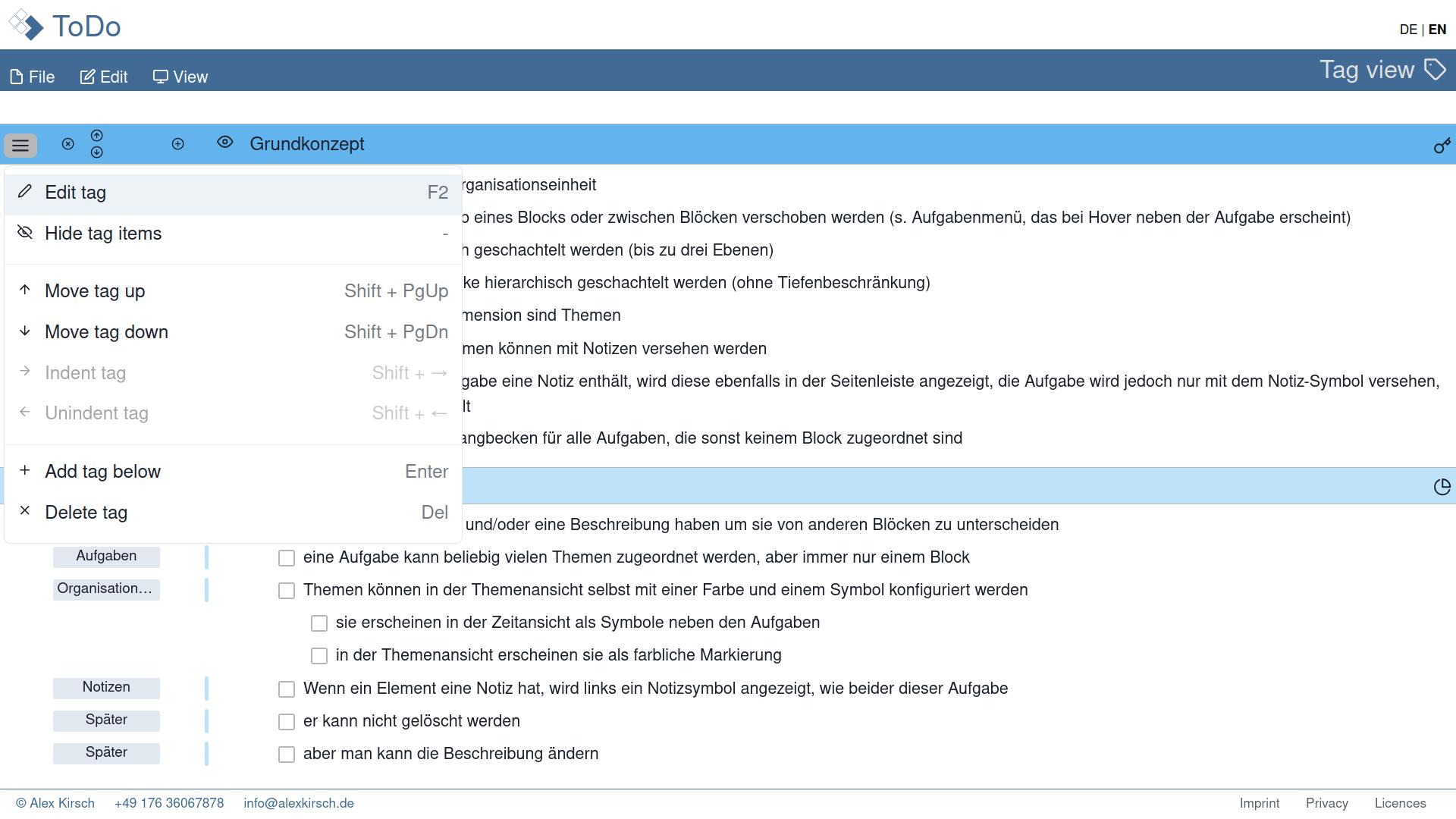
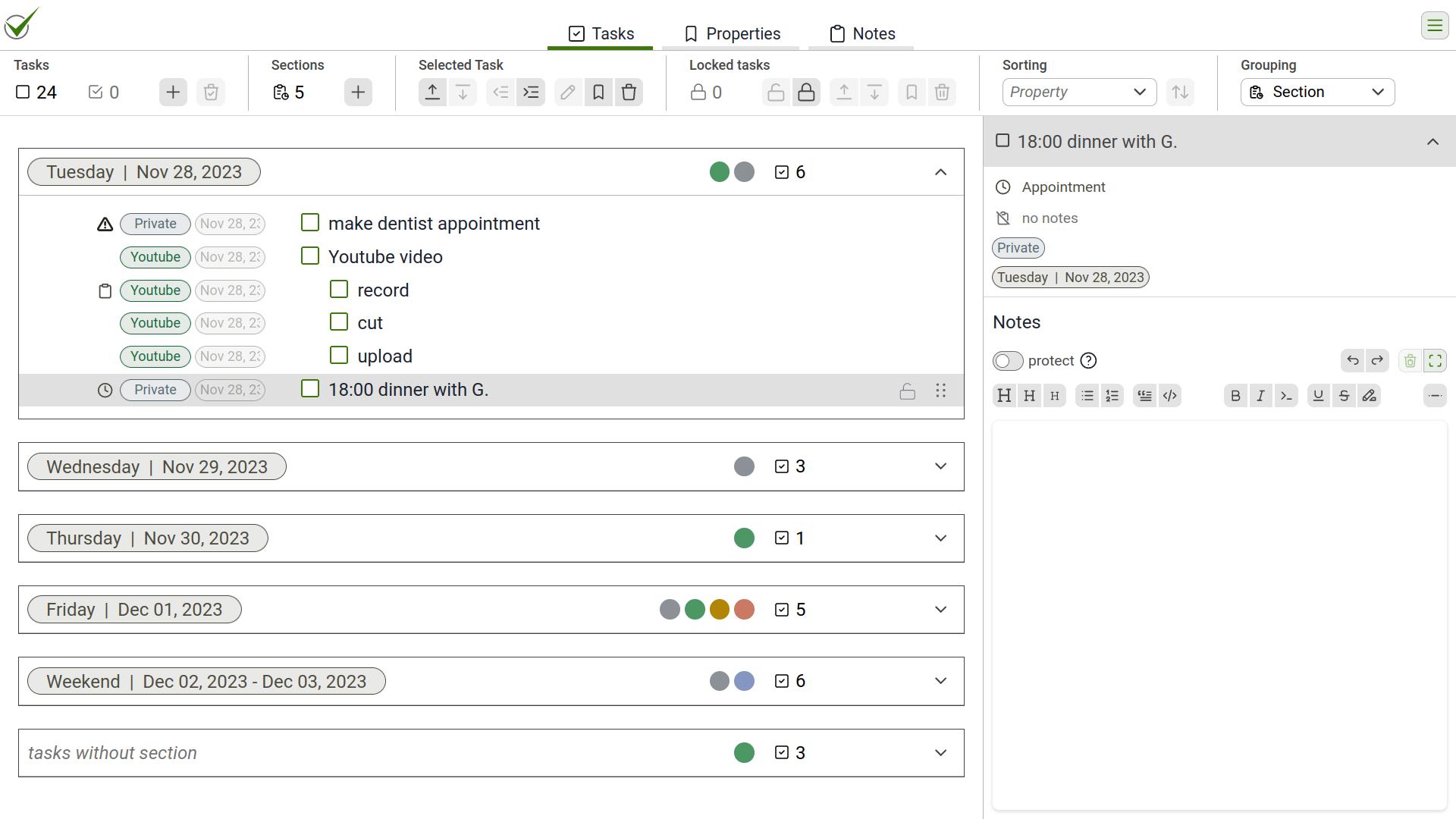
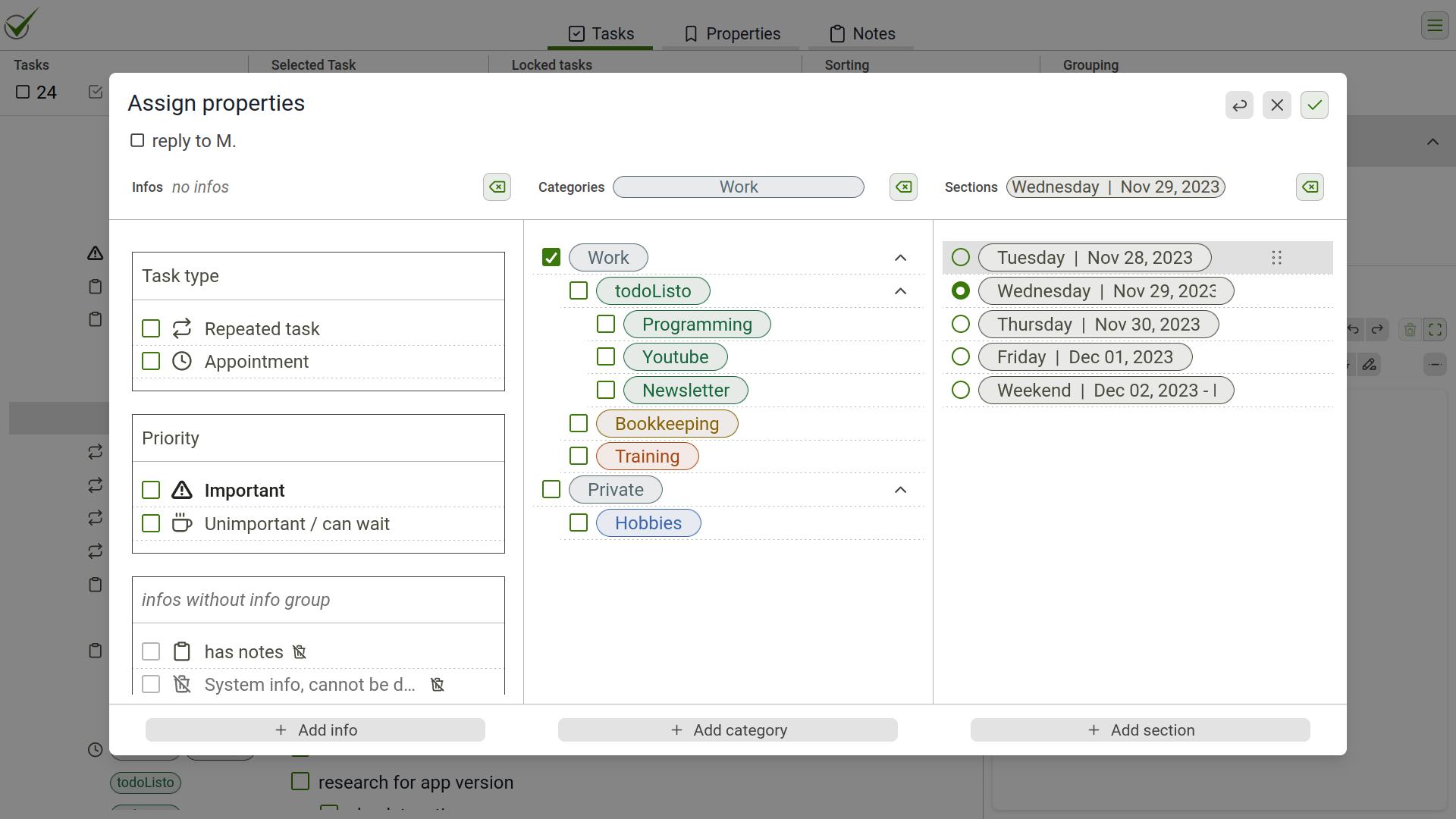
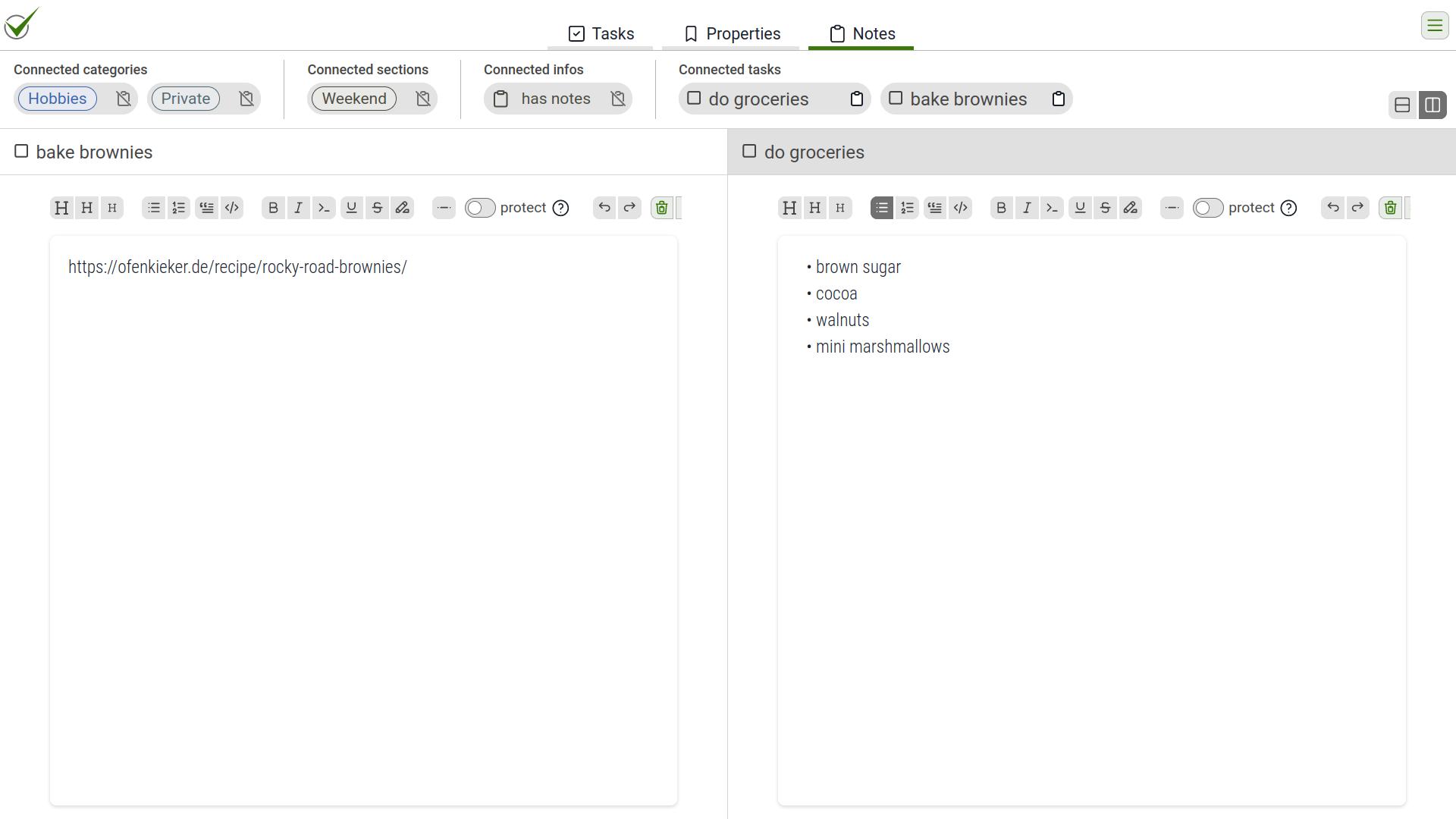
So over time, I turned to more traditional methods such as a toolbar. But in todoListo, I didn't only want to provide functionality, but also information about the objects on the screen, rather like an object in object-oriented programming where a certain type of item (e.g. the task list) has properties (such as the number of tasks) and functionalty (like adding tasks or deleting finished tasks). Here is a little galery of how the dashboard came to life:
 Local interaction: Functionality attached to objects: small buttons that are always visible when the object is activated and a menu with the functionality explained. None of my test users liked the visuals or liked to use it.
Local interaction: Functionality attached to objects: small buttons that are always visible when the object is activated and a menu with the functionality explained. None of my test users liked the visuals or liked to use it.

dashboardin the top bar and functionality attached to objects in reduced size. While the local menu is discoverable with the tool button, the icons may be difficult to understand (they had tooltips to explain their functionality). The rendering was rather inefficient, because every item on the to-do list needed its own menu.


finaldashboard (as of February 2024). All information about the tasks and all functionality connected with them is displayed in a central dashboard in a clean and simple visual style.
The decision for the final solution involved usability aspects (heuristics and observations from the prototype) and technical aspects (like the speed of rendering). Trying and re-trying long enough finally leads to good solutions, but this is only possible (or at least advisable) if you write productive code, because every iteration makes code less readable and maintainable. You could argue that I could have achieved the same by carefully designing the interaction before starting to implement. The visuals might have been cleaner from the start, but I doubt whether I would have made the right decision of where to put the buttons. Only the interaction—the daily interaction with my real to-do list—showed what really worked.
Data Structures: Working with Hierarchies
One simple feature (that I had not really considered as a feature before I started to code) are subtasks, i.e. tasks that are indented and thus are considered as being a subtask of the task above that is not indented. Hierarchies are easy to represent as a tree
structure, is a standard data representation. What I had never thought about, is how to manipulate such a tree when moving objects around, so for example, when you want to move a task up or down on the list or indent it. You always have to make sure to manipulate that tree structure in exactly the way a user would expect the outcome to be. Again something that you can evaluate best when you use it in a graphical interface.
In my prototype this tree structure was causing trouble all the time. For example, when you delete a task, you have to know where it is in your hierarchy and delete it from there in a way that the final hierarchy is still valid. When the task you delete has subtasks of its own, what should become of them? You have to move them one level up. This sounds easy, but you always have to manipulate different parts in your tree, depending on the operation and how you represent your tree. It turned out that some tree representations work better for deletion, others for moving tasks, while others are better when you want to render the content on the screen.
When I started to implement the real program, I took some time to carefully design the data structure representing trees and to identify the basic operations on that tree structure. Again you could say: Why didn't I do that from the start? It is not exactly surprising that I would have to support such operations. But doing so only on a theoretical level is extremely hard: you have to see what happens with each operation, so you need some graphical representation anyway. And there are so many combinations (items can be nested to any level) that I am sure that developing the full algorithm from scratch would have cost even more time. By prototyping I was allowed to do it wrong before I had to get it right.
Features: Infos to the Rescue
While I was using my prototype, I realized that I still did not get the full overview over my tasks as I wanted. I was using the tags so much, that a typical task had three to five categories.
So I was considering different ways to provide a better overview. One idea was a sophisticated system of filter mechanisms and templates that would help to set filters more quickly. Another consideration was to create different dimensions for tags. Instead of one type of tag there would be three: categories for what the original tags were meant to be, infos for more generic tags, and sections that were represented as a concept of their own in the prototype.
One obvious benefit was that I could implement the same mechanisms for all three types of properties, saving on special cases that I had to deal with in the prototype. But another not-so-obvious benefit was that I could eventually do without the sophisticated filter mechanisms that I had planned. Just implementing these three types of properties gives the user more freedom in how to categorize tasks. And just grouping along the different dimensions is a kind of filter. I had not expected that the simple addition ot another property dimension would declutter the tasks so much that no complicated filtering would be necessary. This not only saved me a lot of implementation effort, but also simplified the user interface.
Simplification: Notes
The notes in the sidebar are the most surprising feature for me. When I had the idea of adding notes I could test them with minimal effort by just using an overlay of a simple text area (that does not support any formatting) to allow users to enter text, with Markdown commands if they wished, and a normal display of the text, rendering the Markdown into, e.g., bold text or bullet point lists. One could switch between the two views with a button or a keyboard shortcut.
With this quick-and-dirty solution I could test whether notes as such were a useful concept. And indeed, in my to-do list today 121 of my 147 tasks have notes, as do 3 of my 26 sections, 23 of my 35 categories and 5 of my 23 infos. Also a survey among my test users revealed the notes as one of the most distinguishing features of todoListo.
Even better than just having notes is the coupling with tasks or properties that deletes notes with the item they are attached to. So when I delete a finished task, its notes get deleted as well. Before that I would also take notes independent from my to-do's (knowing very well that I would never look at them again), but not remember I had taken them in the right situation. I would find them years later, and even then I would be reluctant to delete them. todoListo can protect
notes from being deleted accidentally. So a user has full control over whether information is deleted, but the pain of deleting obsolete notes is removed, leading to much more focus on the notes that are still relevant.
The notes show how naturalistic prototyping reduces risk. When I added the notes, I had no idea how useful they would be. Rich-text editing is a rather complicated issue. Even in the final software I am using a library to do this. But even then, you have to spend time selecting the library, getting to know it and adapting it to your needs. This is a major time investment and I was glad I knew that it was worthwhile.
The Value of Prototyping
Summing up the use cases from above, naturalistic prototyping has at least the following advantages:
- Risk and cost reduction by
- being able to stop a project before investing to much;
- clarifying the scope, thus avoiding implementation of unnecessary features (which also improves any user interface);
- enabling a playful approach without having to consider code maintainability as in productive software.
- Shaping expectations:
With running software stakeholders don't just talk about it, but can experience it. This means you- avoid misunderstandings,
- recognize technical and usability issues early,
- can evaluate the project's benefits (or lack of them) in its intended usage context.
- Facilitating project planning
Estimating the cost of a software project is notoriously difficult. The observed effort for the prototype can serve as an anchor for estimating the costs of the full implementation. Some numbers on this are given in the following parts of this blog.
Moving On
When does prototyping end? All I can say is that you will feel it when you are there. When you find that changes or new features start to become a real effort, this is usually the time to stop. Because then the cost advantage will go away and you will just work with messy code (like in old, grown software that has not been properly maintained).
That moment is certainly a good time to consider the potential costs and benefits of the whole project. The experience from the prototyping phase will give you some guidance for estimating both.
There is also the question of whether or how much code you can reuse from the prototype. My advice is to always start from scratch with a fresh project. If there are parts in the prototype that work well and the code is clean, you can copy them over carefully.
The following parts describe what came next for todoListo.
- Sources of Power: How People Make Decisions. MIT Press. 1999.
- Conditions for Intuitive Expertise. American Psychologist, 64(6), pp. 515 – 526, 2009.
Part 3: Beyond Prototyping
23/02/2024A high-fidelity prototype is often confused with working software. With my experience from todoListo, I explain why productive software development is more costly than prototyping and I provide some data for estimating the additional effort. …
Part 3: Beyond Prototyping
23/02/2024While the prototyping phase was a time of constant discovery and excitement, the implementation of the final system felt like it would never end. At times it felt like the more code I was writing, the more was still to come. Here is my analysis of why this happens (not just in the case of todoListo, but in general).
Time Scales
One of the main misconceptions that I have observed in different companies is that people confuse prototyping with software development. The point of a prototype is to be quick, and that implies it may be dirty. Productive software that is developed in the same way (or with the same budget) is not only error-prone, but unmaintainable. And that means it cannot grow and improve. And that means that companies get stuck, whether it is a software product they are marketing or whether it is their internal processes that get blocked. Dead software is sometimes worse than no software. Without software, people can save the day with their creativity, but with bad software they are stuck with limited and erroneous functionality.
As mentioned in the previous part, prototyping helps to estimate implementation time. Estimating time in software engineering is a rather useless endeavor. The problem is that you usually consider the steps that you anticipate. But the time sinks are usually things that you do not anticipate, most prominently bugs. If I were planning for a bug, I would not code it in the first place. So any error is unexpected by definition and there are myriads of ways to produce errors. But with an implemented prototype, I already had a chance to put in some bugs and had to fix them. So bugs get automatically included into the estimate. Of course, we won't make the same mistakes again in the productive system, but we will have many more opportunities for new bugs, so the factor of unexpected things should be about the same.
So here is my data from todoListo: I spent about 300 hours on the todoListo prototype, including the revision of the concept.
The full implementation
took about 1500 hours. That is a factor of five. The full implementation contains additional functionality of the server backend. The pure frontend (what is now the Footloose
version of todoListo) alone took about half that time, i.e. 750 hours. That is still a factor of 2.5 compared to the prototype. In general, I would work with a factor of (at least) three to estimate the time needed for a productive version of a prototype. Here I was a bit quicker, but the prototype was rather sophisticated (I was using with it every day) and I was the one to do the implementation. Usually the learnings of the prototyping phase need to be shared with and transfered to other team members or stakeholders.
Hofstadter's Law in Action
Hofstadter's Law: It always takes longer than you expect, even when you take into account Hofstadter's Law.[1]
If we already have a pretty well-functioning prototype and we have a clear concept of what the productive system should do and how its architecture should be structured, shouldn't the implementation be quicker than in the prototype? The prototype included the time to develop the concept and in my calculation also the design of the interface and main data structures. How can the productive system need more time?
An obvious point is that a productive system usually contains more features. All the things that were left out in the prototype as being too generic now have to get in. These are often features that users just expect nowadays, such as the drag-and-drop functionality in todoListo. And those features are more costly than the features in the prototype, because if they were easy to get, you would have included them in the prototype.
More generally, a productive system needs a lot more attention to detail. For example, to signal an error to the user, in a prototype I will just output a message on the command line (so a normal
user will not even see it). In a real user interface, we have to show a decent message and offer ways to continue. This needs additional thought and can even lead to major redesigns.
Another issue with productive software is that errors are not easily forgiven. In a prototype that is used only by the creator and maybe a handful of test users, who are aware of its shortcomings and its status as a prototype, errors can be expected and tolerated to a certain degree. But in a productive system, even small errors lead to major confusion and dissatisfaction.
Summary
When you develop software (no matter if you are a develper or some other kind of stakeholder), print Hofstadter's Law in large font, put it over your bed and say it three times before you go to sleep every day. Even then you will underestimate the costs of your software, but you will be less disappointed.
It is hard to explain why software development takes so long and is so expensive. As mentioned above, some of the issues are
- errors can never be planned for,
- errors in productive systems are not as easy to tolerate as in prototypes,
- additional features and details require a disproportionate effort.
More problems arise when using third-party libraries or components and when the system is distributed. Learn more about this in the next part.
- Gödel, Escher, Bach: An Eternal Golden Braid. Vintage Books. 1979. pp. 152
Part 4: The Cost of Convenience
01/03/2024Storing data in a central place to be retrieved from anywhere is a standard convenience. Because it is so common, it is easy to forget how complex distributed systems are. Standard components, e.g. for authentication, are a prerequisite to enable even small players like me to implement such systems. But the choice and use of third-party systems is a major cost factor that is often overlooked. …
Part 4: The Cost of Convenience
01/03/2024One of my reasons to develop todoListo beyond a prototype was that I was tired of keeping isolated to-do lists on different computers. I wanted my data in a central place, so that I could access it from anywhere and could enter new tasks on the phone whenever they occured to me. This sounds like a standard feature: storing data in a database. What can be so difficult about that?
Distributed Systems
When you process data on different systems (like a frontend in the user's browser and a backend on a remote server), you suddently get a lot of uncertainty. You never know if one end is offline, or if a message has been lost or sent twice. None of the system components can be exactly sure of what is happening on the other side.
Then you have to take care of data security. You need mechanisms to identify and authenticate a user. And you have to ensure that data is never sent around without encryption. And then there are issues to trade off data availability and data security. If you store data inside a user's browser, outside attackers won't be able to access it. But what if the user shares his computer with other users?
Another issue was how to coordinate several frontends. A user may have opened todoListo on her laptop and on her phone. When she enters something on the laptop, she would expect this change to be shown on the phone, too. Or, at least, we have to make sure that one change does not cancel out the other. To do this, I had to add yet another technology: Server-Sent Events. This meant I needed to figure out how it works, whether every browser supports it, had to make sure that no disasters happen if it fails etc.
All of these issues are solvable, but at a cost. For example, the undo and redo functionality in todoListo. For the prototype I could simply use a library, it took me about half an hour to add it and it just worked. Add about half a day in the final frontend to figure out some details, e.g. not to allow the undoing of opening a popup. For the distributed system I estimate that it has cost me a total of about five full working days to implement and test that the frontend and backend were doing the same thing. And thinking more long-term: by adding the backend, I also had to make the code in the frontend more complicated. This means that—compared to not supporting undo or redo—my code is harder to read and that means that any change takes longer, even changes that have nothing to do with the undo/redo functionality.
"The" Backend?
The backend I envisioned was not supposed to do a lot: Store the to-do list for each user, receive changes on it from the frontend and store them. And when the user opens todoListo in another browser, compute the full to-do list and send it to that browser.
As a prerequisite, my backend program must be connected to the internet somehow. So I needed a library to create a web server and allow it to receive messages. For a permanent data storage I use another standard method: a database. I already mentioned authentication, another system. So we have at least three programs running.
So the
backend is rather an ecosystem of different species interacting. And that means you have to run them together to know how they work. While you test, you don't want to interfere with your productive system. So you want to set up different instances of this system of components, for example one for developing new functionality, one for testing the complete system and one as the final productive system. That means you have to package
those components to make sure the correct versions and parameters are running together. I don't want to go into details here, but there is a whole field called DevOps
that is developing and using tools to do that.
So for even seemingly simple functionality, you need a whole zoo of programs. When I complain about this, the unanimous reaction is
Hasn't someone already implemented that? Isn't there a tool you can use?And the anser is: YES, of course there are tools.
Hidden Costs of System Reuse
Before going into the costs, let's first talk about the benefits. It is amazing how much software is available today. Instead of complaining that I only wrote a small fraction of the code running in the todoListo backend, I could just as well rejoice over saving so much work. Without libraries and software components from others, it would be completely impossible for a tiny player like me to offer a software such as todoListo at all.
What I want to show here, is not that it's a bad idea to use third-party components, but that they, too, come at a cost, even if the license is free of charge.
The first understimated cost is the time you spend deciding whether to use a third-party system or whether to implement yourself, and then selecting particular components you want to use. Whether it is a library, a software component or an online service, you will be married to this system for a while, so you better make sure that it does what you need it to do. And it is always a strategic decision: you can never be sure that it will still exist next year. And if it does exist, will it be maintained, especially when it is security relevant? Or maybe the component will be developed into a direction that does not fit your requirements. Or maybe it will be taken over by another company or organization that you don't trust or that will be changing the pricing model. All of these consideration take some time and you must be prepared that in the future you may have to make big changes in your code if third-party components change considerably. So just the dependency on third-party systems is a risk and a cost factor of its own.
The second underestimated cost is the time you need to get familiar with the third-party system. For example, for user authentication I am using a tool, because I am not an expert in authentication protocols. Of course, nobody writes a tool just for me. So the tools are written in a way that they can be adapted to different use cases, which means they offer parameters to tweak. But for setting the parameters right, you have to understand them. And that means that you do have to spend some time understanding at least a tiny fraction of the authentication protocols. Each third-party system comes with its own set of parameters, tooling and languages. For example, to customize the login screen for todoListo, I had to edit files in FreeMarker format, which is somehow similar to HTML, but has additional features. And the variables used therein are specific to the authentication tool.
The time you have to spend on learning those languages, is by far less than having to fully get into the algorithms and implement them yourself. But it is still time, and it requires a lot of mental flexibility. In a single day, I may be using ten different programming and markup languages. And this leads to another hidden cost and risk: The whole point of using third-party software is to run it without fully understanding the details. But at the end of the day you have to take full responsibility for your final system, and that is practically impossible.
The third underestimated cost is the maintenance. A major problem in most organizations is that they consider software as something static. In the old days, when a single person could still write a complete program on her own, this was even somehow true. If the program does what it does, why change it? But any program runs on an operating system (or maybe even layers of operating systems: todoListo runs in a browser, which is itself a mini operating system). Operating systems get updated, because the hardware gets faster and with it the expectations of users, and because of security. Security is always an arms race: when one side sets up better security mechanisms, the other will try to circumvent them. So security is a constant requirement for updates, not only in operating systems, but authentication software, web servers and browsers. And in any software users ask for more features. Be asured that your third-party systems will change, and your system has to change with it.
Even if your system is not directly security relevant, not updating regularly will kill your software sooner or later. I tried it once. I was using a simulator for autonomous robots in my research. My PhD students had made some additions for our particular work, which meant that it was a bad idea to update the simulator. So I kept on using the old version. But this also meant that I could not update my operating system, because that would have changed the default Python version and that would have broken my old simulator. Finally, the operating system version ran out of its support time, so I would not get security updates and so it became a security issue. In the end, I updated my operating system and I changed to a new simulator. Getting my experiments back to run took me about a year. What this story shows us: you pay the maintenance cost eventually. You can choose whether you do it in small portions as you go along or the hard way as I did.
The Cost of Complexity
We can boil all this down into the general problem of complexity. Here are a few numbers of how the additional complexity of a central data storage affected the effort for todoListo:
- About half the total effort went into the frontend (see Part 2).
- The other half split like this:
- Not quite half of the time went into programming the backend (including the use and familiarization with libraries).
- About a quarter went into figuring out the rules of the subscriptions and integrating the payment provider.
- The rest went into infrastructure: setting up the database and other third-party software, configuring the systems, setting up and configuring the Docker container.
If complexity is expensive and risky, can we do something to avoid it? Let's look at sources for complexity and what we might do about them
- Distributed systems: networks require additional measures to ensure security and reliability.
If you can avoid distribution, great. The problem is just that in our networked world, the distribution of data or computation is often a basic requirement. In the case of todoListo, I would have nothing to sell without it. - Heterogeneous systems: need work for selecting, setting up, orchestrating and maintaining the different components.
Using third-party systems is often unavoidable and can save a lot of effort. But I often see a kind of knee-jerk use of external libraries, software or services. Just because there is a system, you don't necessarily have to use it. Be sure that any system that you use covers difficult functionality that would be costly for you to implement. Also be cautious about fashions. For example, with the availability of graph databases (and propaganda by big tech companies), everyone seemed to have to use them, while standard relational databases often work just as well and are better understood and come with established tools. - System size: even if an organization can afford to do everything on their own, for huge systems it will need several teams to work on the different components and the situation will be similar to using third-party software.
Another fashion is to package more and more functionality into big software systems. This is convenient, because you can use one database and show data consistently in different parts of the system. But I often wonder if the stakeholders are aware of the complexity that comes with increased size. On the other hand, having distributed data sources with diverging data, is no fun either. The best solution I have to offer is to cut back on expectations and to simplify business processes whenever possible. A simple copy and paste between programs is not a lot of work, but can save a fortune in software development and maintenance cost. - Feature requirements: particularly dangerous are any kind of special cases, but also convenience features that are simply expected because they are everywhere (such as the undo example above).
Similar to the size of the software, we should be very cautious about which features are really needed. Could todoListo do without undo or redo? I think not. Especially for new users, you want to be sure that you cannot destroy your data with a single button click. An example where I did limit functionality is when users work on different devices. Since todoListo is made for single users, there is no need to fully support the simultaneous interaction from different devices. A user will hardly work with one hand on the laptop and the other on the phone. todoListo can handle such situations so far that the data will not break, but some user input may be rejected.
In many cases, the complexity of software is driven by our environment. We use networked devices, we are accustomed to certain conveniences and sometimes we are even forced by law to comply to certain standards of digitization. For example, in Germany there is a new law that invoices in B2B interactions must be machine readable
. This means in practice that freelancers and small companies who used to write their invoices in a text processing program are now forced to use a tool that supports one of the permitted formats (or for if your are an IT geek to spend time implementing and maintaining such a tool yourself).
Since we cannot fully avoid complexity, we should at least mentally prepare for it, especially when budgeting IT projects. And we can learn to become more conscious about the costs of convenience. Not every user expectation has to be fulfilled. Especially for software for internal processes in a company, you have options to simplify the processes and to consider the trade-off between uncomplicated manual work and intricate software development and maintenance.
I am glad that I could make the hard decisions in todoListo myself, to decide where I invest my time and where I can cut corners. This is a skill that can best be learned when you have to suffer from the consequences yourself. These learnings are summarized in the next and last part of this blog series.
Part 5: Looking back and forward
01/03/2024todoListo has been the most valuable experience of my life. A reflection on the process of getting so far and how it goes on in an interview with myself. …
Part 5: Looking back and forward
01/03/2024You have worked on todoListo for more than two years. How does it feel to see and use it as a productive system?
It feels wonderful! I have never had the chance to do a full project from beginning to end without asking for anybody's money or permission. And todoListo has shown me that I can do it, if I just have the freedom to make the decisions. And it's fun to build a brand and identify with the product. Getting a decent logo was a bit of a drama, but once I had it, I loved it, and now I have to be careful not to exaggerate surrounding myself with todoListo merchandise 😊.

What has worked well, what would you do the same way again?
I didn't set myself any rigid goals or timelines. Everything evolved gradually and I never knew how an idea would develop. I was also aware that nothing is ever finished. Whether it's a user-facing feature or some kind of infrastructure work, you will always have to change it, either because something external has changed, such as an external API, or by testing and working with it, it has turned out that something can be improved. My motto has been trust the process
. Whenever a problem seemed unsolvable, I knew if I gave myself the time to think about it and to try different approaches, I would get a decent solution in the end. Sometimes it took months and several iterations of change, but it has always worked. And, of course, the process goes on.
What was your biggest mistake?
Underestimating the time, pain and desperation it takes to implement productive software. When working on the prototype, I had a feeling of constant progress. But when it came to the real
system, there were times when it seemed that the more work I was putting in, the more open ends I created. This was reflected in my to-do list in todoListo: at times I had about 220 tasks on my list (my normal number is between 100 and 150). That could be really frustrating.
Would you have started todoListo if you had estimated the time and effort correctly?
Probably not. But I didn't only underestimate the effort, I also underestimated the potential for learning and personal growth. todoListo has been the best professional experience in my life and it is impossible to put a price tag on this. So in this case I am glad I did not seriously estimate the effort before I started.
Did you ever think of giving it up?
Not seriously, but there were times when I was doubting whether I could ever get todoListo to a point of releasing it. I had formed a plan B
to publish only the footloose version, which is so much simpler than the connected version with the backend. But todoListo itself kept my motivation up, because I could see every day that it was fun to use and that its organization principles helped me to get back to reality and just accept that there is still a lot of work to be done. The problem is not that we work too slowly, the problem is that we expect (or rather hope) to get away with less work that it actually takes.
Would you do such a project again?
I was once traveling in Sri Lanka, climbing Adam's Peak, which is a sacred mountain that you climb at night to enjoy the sunrise when you arrive (in pilgrim season, forget about seeing the sunrise, you will only see people around you, but this makes the experience even better). Our guide told us that Sri Lankans say that you should make the pilgrimage once in your life, but climbing that mountain several times in your life is slightly mad. I feel similarly about todoListo: It was a wonderful experience to build a complete software system on my own. No business analyst or designer or software developer or DevOps specialist ever gets to do everything together and I had that privilege. But I still enjoy the first step, the prototyping, the most, and for future projects I hope I can do more of it and see the projects being continued with a team that shares the burden for the productive implementation.
What comes next?
Of course, the todoListo journey continues. I have more ideas for new features and there are always little things to improve or update. But, while the last few months were dedicated only to todoListo, I want to get back into working on different projects. I hope I will get the opportunity to use my experience from todoListo in client projects and further projects of my own. Since I have covered all those different roles in this project, I feel myself more than ever in a position to build bridges between different professional disciplines.