What is AI?
Part 1: The original definition
04.01.2019A fundamental problem in the public discussion is the missing definition of Artificial Intelligence. In this blog series I provide possible destinctions of AI from non-AI. Whatever anybody believes AI to be, one should make the definition clear before starting any discussion on the impacts of AI. …
Part 1: The original definition
04.01.2019I usually try to avoid any definition of Artificial Intelligence. There is no well-agreed definition of human intelligence, therefore it seems pretentious to find one for the artificial variant. I have changed my mind, however, since AI is discussed in so many different variants—often in the same text. The usual story goes "We already have AI or are very close to having it, therefore AI development will accelerate and destroy/save humanity." The problem here is that the definitions of AI change from phrase to phrase, but since the same word is used, they are mingled into one.
Let's go back to the time when the term "Artificial Intelligence" was coined, to 1955. Computers were still a rarity, being a treasure of any university that could afford one. People might just have been happy to have a tool for doing fast computations. But the idea of thinking machines is much older than computers, and with the now available remarkable power of doing arithmetic, old dreams were rekindled. In 1955 John McCarthy organized a workshop titled "Dartmouth Summer Research Project on Artificial Intelligence" and thereby coined the term. The proposal [1] starts as follows
We propose that a 2-month, 10-man study of artificial intelligence be carried out during the summer of 1956 at Dartmouth College in Hanover, New Hampshire. The study is to proceed on the basis of the conjecture that every aspect of learning or any other feature of intelligence can in principle be so precisely described that a machine can be made to simulate it. An attempt will be made to find how to make machines use language, form abstractions and concepts, solve kinds of problems now reserved for humans, and improve themselves. We think that a significant advance can be made in one or more of these problems if a carefully selected group of scientists work on it together for a summer.This paragraph shows the definitional problem of AI from its very beginnings: the generality of the methods. If a machine is expected to learn, did they mean that it can learn anything in any circumstance or would this learning refer to one specific problem (in this case learning could simply mean storing new values in a database)? Solving problems reserved for humans, do we have to find one method that solves them all or are we happy with a tailored solution for each problem?
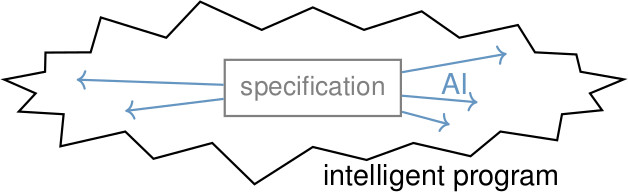
The zigzaged area in this picture represents a tough problem that requires human intelligence. One interpretation of AI could be to write a computer program that solves the complicated task equally well as people do. This would be a typical engineering task, so why invent a new name for it? I think what McCarthy and his colleagues had in mind was the process shown in the middle. Instead of handcoding the complete task, we would like to specify some aspects of the task (we somehow have to tell the machine what we want from it), and this simple specification would expand by AI mechanisms into the more complicated program. There is still a lot of room for interpretation: how big or small is the central specification, how much is added by "intelligent" mechanisms, how much is so specific to the task that it has to be implemented manually?
The picture also illustrates two possible ways to develop AI: from inside out or outside in. Alan Newell and Herbert Simon followed the first approach. They started early with the Logic Theorist and later the General Problem Solver to develop general mechanisms that solve a wide range of problems (not necessarily any problem). Even at the Dartmouth workshop it became clear that the outside-in method would simplify funding [2]. Working on specific problems, one might gradually identify commonalities and thereby extract more general mechanisms. I think both approaches are important and should interact.
But do we know now what differentiates AI from non-AI? The AI arrows represent what any software library does: extending a simple specification of a frequently occurring problem class into a more complex solution.
I will not be able to give you any real definition of AI, but I will provide several perspectives from which you can create your own understanding (or perplexity) of what AI is.
Part 2: Strong, weak and no AI
13.01.2019Following up on the question what destinguishes AI from non-AI we look at the more fine-grained distinction of strong vs. weak AI. …
Part 2: Strong, weak and no AI
13.01.2019We have seen how AI started with an intuitive notion of reproducing or simulating intelligence in the form of a computer program. The open question was how general the methods have to be to deserve the label AI as opposed to standard engineering.
The idea of intelligent machines has been taken up by philosophers to discuss whether this goal is possible or desirable. John Searle considered AI to be impossible, because a computer can never be "conscious", illustrating the idea in his famous Chinese Room thought experiment. He argued that outward intelligent behavior (which he assumed wrongly could be implemented with simple rules) is distinct from consciousness. I have always wondered why anyone bothered to respond to such a foolish argument. But they did and the solution was a split of AI into imaginary subfields:The claim that machines can be conscious is called the strong AI claim; the weak AI position makes no such claim. [1]
Psychologists and neuroscientists avoid the term consciousness since it contradicts the generally accepted view that human behavior stems from physical, albeit very complicated, processes. But if we just follow fixed mechanical rules, is there anything such as free will? And we all feel something like consciousness, where does it come from? Current scientific methods cannot answer these questions, and therefore, they are usually considered to be outside the scope of science. This also implies that strong AI is not worthy as a scientific endeavour as it involves the notion of consciousness.
Coming back to the original endeavour of understanding and reproducing intelligent behavior with computers, to make philosophers happy, we call it weak AI and ignore the consciousness debate. But this is not the end, unfortunately. Some people seem to equal intelligence with consciousness, and consequently no consciousness implies no (general) intelligence (in exact contradiction of Searle's argument). In this way, the original idea of AI got thrown into the strong AI box, which had already been labeled as unscientific.
What remains is the weaker version of weak AI, also called narrow AI: solving small, well defined problems. This field has been celebrated as having made tremendous achievements in the last decades. Apart from the little detail that these achievements had nothing to do with the understanding of intelligence (they are mostly due to the increase in computing power and infrastructure), how are they different from any other type of computational engineering? They are not, and they should not be called AI.
The narrowing of AI down to standard engineering is correlated with the dilemma of funding. Specific applications with well-defined goals are more justifiable, graspable, and achievable in the short time horizons of third-party funded research projects, and therefore the easier path for most scientists. AI in the sense of general mechanisms that are applicable to a wide range of problems, is so hard that we have not even found the right research questions. In an ideal world this would be seen as a challenge. But in the world we live in researchers are forced to tackle small, simple problems to be able to publish at the prescribed pace. Instead of producing, you would have to sit back and think, very likely thinking in the wrong direction most of the time.
In my opinion, the distinction of strong and weak AI has damaged the field and contributed to the confusion of what we want to call AI. The celebrated successes all fall into the domain of narrow AI (the weakened version of weak AI), while the scenarios of thinking robots that take over the world (for good or bad) are based on very optimistic (not to say unrealistic) expectations of general AI (the general version of weak AI or even strong AI).
- Artificial Intelligence — A Modern Approach., 1 th edition. Prentice-Hall. 1995. pp. 29
Part 3: Are we already there?
27.01.2019Some traditional applications of AI have been solved by now, such as playing Chess or Go. Is AI a moving target that gets reset every time an AI problem is solved? …
Part 3: Are we already there?
27.01.2019The Dartmouth workshop attempted to "solve kinds of problems now reserved for humans" [1], "now" meaning 1955. Doubtless, computers today can do many things that had to be done by humans in 1955. From this viewpoint we could savely claim that we are done, AI is solved.
On the other hand, Alan Turing's 1950 prediction that "at the end of the century the use of words and general educated opinion will have altered so much that one will be able to speak of machines thinking without expecting to be contradicted" [2] has turned out wrong. Intuitively, people expect an intelligent machine to be something like R2D2 or HAL 9000. But is this too picky? Several traditional problems of AI like playing chess or Go are now being solved by computers beyond human skills, leading some AI researchers to feel that their task is redefined any time they make progress:
Curiously, no sooner had AI caught up with its elusive target than Deep Blue was portrayed as a collection of "brute force methods" that wasn't "real intelligence". [...] Once again, the frontier had moved. [3]
To better understand this dispute, we have to differentiate between AI applications and the goal of AI in general. In 1950, before the term Artificial Intelligence was coined, Alan Turing proposed the "imitation game" (now known as the Turing Test) as a means to define intelligent machines [2]. He suggested that in a question-answer game a person converses with two other entities, one a machine, one another person in a kind of chat so that the questioning person gets no clues from vision or voice. The questioner can ask the other two anything she likes in the attempt to distinguish the person from the machine. If, in such a game, the questioner is unable to differentiate person and machine, the machine can be said to be intelligent.
At the end of the same paper, Turing suggests how one would go about developing such programs.
We may hope that machines will eventually compete with men in all purely intellectual fields. But which are the best ones to start with? Even this is a difficult decision. Many people think that a very abstract activity, like the playing of chess, would be best. It can also be maintained that it is best to provide the machine with the best sense organs that money can buy, and then teach it to understand and speak English. This process could follow the normal teaching of a child. Things would be pointed out and named, etc. Again I do not know what the right answer is, but I think both approaches should be tried. [2]He mentions application fields that have become typical problems of AI and are also mentioned in the Dartmouth proposal: using language, playing chess, learning. Here is the crucial point: Turing considers these as steps towards building intelligent machines, not as tests for intelligence.
If we follow Turing, the only test for intelligence is the Turing test. Solving single problems such as chess, Go or even automatic translation, may be steps towards intelligent machines, but are not as such to be called intelligent.
We could now conclude diplomatically, saying that we are halfway there. We do not have machines that display general properties of intelligence, but we do have isolated programs that perform tasks that seem to be good candidates to work on for achieving full AI eventually. But I think there is an element of "cheating" in the AI applications in existence today. I think Turing and the Dartmouth consortium were assuming that researchers working on AI would have the global goal of intelligent machines in mind, using the applications as stepping stones towards this goal. By interacting loops of working on applications and the big picture, we might eventually create machines that we would intuitively consider as being intelligent. What happened, however, is that AI applications are being persued as goals in their own right and the far-reaching goal plays no role at all.
The successes are largely due to developments outside AI, especially on fast computers and improved infrastructure, such as the internet. IBM Deep Blue's success relied on a mixture of heuristic search methods, expert knowledge of chess, and extremely fast computers. The only part AI played in this, is the heuristic search, which had been explored since the 1950's [4] and had basically been solved by 1968 with the A* algorithm [5]. IBM's Jeopardy-winning machine used a range of known AI techniques [6] as well as the whole of Wikipedia (and more data) on an extremely fast computer. Google's Alpha Go is often presented as an instance of the ultimate learning machine. Reinforement learning was used by Arthur Samuel in his checkers program in 1956 [7]. Even Deep Learning is not really new [8]. The main reason why this could be done today are immense computing ressources. The generality of the method does not even extend to any type of computer game, let alone realistic tasks [9].
Sometimes small changes in known technologies have a huge impact. Just because the mentioned examples use enormous computing resources, they could still be the key to intelligence, could they not? A year after IBM's impressive demonstration of Watson in Jeopardy in 2011, I witnessed experienced AI researchers at a conference fighting about whether Watson was a game changer or just old stuff reheated. At that time I was unsure myself. But looking back, in the seven years since this demonstration, I see no fundamental change of AI. Using Watson technology for other requires much more preparation of data than IBM likes to admit [10].
Defining AI in terms of applications leads us back back to the distinction of narrow and general AI. In the narrow sense of implementing cool and sometimes even useful applications, we already have AI. But in the sense that most people associate intuitively with intelligent behavior, we have learned almost nothing from those applications.
- Computing machinery and intelligence. Mind, 59(236), pp. 433 – 460, 1950.
- Artificial Intelligence and Life in 2030. Stanford University, Stanford, CA, September 2016. (One Hundred Year Study on Artificial Intelligence: Report of the 2015-2016 Study Panel)
- The Logic Theory Machine: A Complex Information Processing System. Tech. rep. P-868. The RAND Corporation, 1956.
- A Formal Basis for the Heuristic Determination of Minimum Cost Paths. IEEE Transactions on Systems Science and Cybernetics, 4(2), pp. 100 – 107, 1968.
- Building Watson: An Overview of the DeepQA Project. AI Magazine, 31(3) 2010.
- Samuel's Checkers Player. In: Reinforcement Learning: An Introduction., 2nd edition. MIT Press, Cambridge, MA.. 1997. (retrieved 27 Jan 2019)
- Deep Learning 101 - Part 1: History and Background. https://beamandrew.github.io/deeplearning/2017/02/23/deep_learning_101_part1.html 2017. (retrieved 27 Jan 2019)
- Building Machines That Learn and Think Like People. Behavioral and Brain Sciences, 24 2016.
- Financial Analyst Takes Critical Look at IBM Watson. https://www.top500.org/news/financial-analyst-takes-critical-look-at-ibm-watson/ 2017. (retrieved 27 Jan 2019)
Part 4: AI Methods
02.02.2019Goals and applications do not distinguish AI from non-AI. Maybe the difference lies in the methodology. …
Part 4: AI Methods
02.02.2019Pursuing AI applications in their own right does not bring us any closer to understanding and building intelligence. But developing an elusive notion of intelligence without specific use cases seems unrealistic too. Applications may show us the way if we do not cheat. By cheating I mean to engineer some application without considering its contribution to the understanding of intelligence. Chess is a good example. It has clearly been solved from an engineering perspective; chess programs can beat any human player. But from an AI perspective chess is still an interesting open problem. Studies of human chess players reveal a lot about thought processes. And no chess program today plays in the same way as humans (which would include making the same mistakes). Very likely such a program will never be written as chess is now considered solved and therefore unworthy of further investigation.
The chess example also illustrates that the measurements of solving a problem are adapted from engineering. Chess happens to be a well-defined problem, which makes it an ideal starting point for AI, since at least you can easily represent it in a computer. And even though the goal for players is ultimately to win games, a more scientific approach would be to understand the process employed by players to make their moves, use the understanding to reproduce it and carry it over to other tasks. Unfortunately AI has taken the easy path by equalling success with the optimality of outcomes. Chess and other well-defined problems are special cases in that they have something like a well-defined optimum. What is the optimal way to drive a car? What is the optimal way to plan a trip?
Equalling intelligence with optimality limits AI research in several ways:
- Researchers prefer well-defined problems over real-life problems, because only for the first optimality is defined and measurable.
- The methodology is limited to "mathematically clean" approaches. If there is an optimum to be reached, we want to be sure that we always get this optimum. But since real problems lack a definition of optimality, those "clean" methods are unlikely to bring us closer to intelligent systems.
- Ideas are only accepted if they improve existing results. This leads to incremental changes in existing approaches, but never to new ones.
So if we do not measure the result of specific tasks, how do we measure progress in AI? I think there is no golden bullet, but here are some suggestions:
- A method has higher value for AI if it is applicable to a range of problems, not just one specific application. Such a measure is hard to quantify. We would need ways to define when two problems are different (is finding a way from Stuttgart to Munich a different problem from finding the way from Munich to Hamburg?), or better a measure of their distance (wayfinding on foot to wayfinding by car should are more similar than wayfinding to language translation). We would also have to specify when a method is the same. We can expect that any method would need to set some parameters depending on the application; calculating parameters needs specific functions; implementing functions is plain programming...
- A comparison to human performance and approaches can indicate a way towards intelligence. Current programs are usually better than humans in specific tasks. I would prefer methods that make the same (kind of) mistakes as humans. Of course intelligent machines could show a completely different type of intelligence as humans. But they do have to operate in the same environment. Human mistakes are in some way connected with our physionomy (such as limited short-term memory), but in many cases originate from the complexity and unpredictability of the world we live in. So at least in some cases a comparison to human behavior seems adequate. We then face the challenge of defining respective metrics [1].
- A related measure is the acceptance of outcomes by humans. The whole point in builing intelligent machines is to do something useful for humanity. So the ultimate measure is whether people find the results useful. The simple question whether someone likes an outcome is often not too revealing. But we can define objective criteria for specific tasks [2][3]
- Using common sense. This point may sound rather unscientific. Shouldn't science rely on objective measurements? I am not suggesting to just trust our gut feeling, measuring is important. But as we have seen, there is no one single metric that would show us whether some method moves towards intelligent behavior. If we want objective, unambiguous metrics, we always end up with optimality. So we have the choice between measuring something well that is beside the point, or measuring important things as good as we can. I prefer the second. And since our measures are restricted, we need to use our common sense to put them into perspective.
By changing the measurement for progress, we would open the door for more interesing approaches. The "successful" part of AI comes down to optimization algorithms. Those can be helpful for well-defined problems, but neither are they unique to AI, nor do they work in unstructured, realistic settings. AI needs a unique set of methods and metrics, not shallow copies of other science or engineering fields. For me the distinguishing characteristic of AI is the way you approach it. It is a mixture of trying to understand natural intelligence and implementing flexible mechanisms that can deal with the complexity of the real world.
- Lessons from Human Problem Solving for Cognitive Systems Research. Advances in Cognitive Systems, 5, pp. 13 – 24, 2017.
- Human Understanding of Robot Motion: The Role of Velocity and Orientation. International Journal of Social Robotics 2018. [pdf from HAL]
Part 5: Take your choice!
10.02.2019As we have seen, AI can mean anything and nothing. I prefer the view of cognitive systems. Whatever you choose to call AI, stick to one definition. …
Part 5: Take your choice!
10.02.2019In my view AI has taken a wrong turn in adapting engineering metrics and methods, making itself as a field superfluous. Even worse, methods developed in other subfields of computer science have been re-invented in AI under a different name, creating confusion about algorithms and hindering collaboration and exchange between engineering fields.
Only few AI researchers have stayed with the original idea of building techniques that apply to wide range of problems. About a decade ago several initiatives have tried to rekindle it under the flag of "Cognitive Systems". Some of these initiatives, like the Advances in Cognitive Systems conference and journal, have survived and are working on systems that serve a wide variety of human needs.
I would prefer the term "Artificial Intelligence" to be abandoned, moving on with the study of Cognitive Systems. But since it is such a strong marketing instrument, I doubt that my wish will come true any time soon. But the least anyone can do is to state which of the many possible definitions of AI one is talking about and to stay with this definition throughout a line of reasoning.
I have heard people considering a dishwasher as intelligent (I agree that it is an intelligent solution, but I disagree that the dishwasher itself posesses any intelligence). Since the term AI has been broadened to any engineering discipline, it is totally valid to call a dishwasher intelligent. But such "intelligent" machines have been around for decades. Why should they suddenly develop superhuman cognitive abilities, take away all our jobs, or rule the world?